Key Takeaways
- AI agents don’t just respond, they decide and act, which is why request-based security tools structurally can’t evaluate them.
- Shadow agents and undocumented MCP servers are the default state in most enterprises, not the exception.
- Passing QA says nothing about how an agent behaves under adversarial, attacker-crafted input.
- An action can be technically authorized and still be the wrong action in context, that gap is what runtime threats exploit.
- MCP is becoming the connective layer between agents and enterprise systems, and it needs controls built for inferred intent, not fixed schemas.
Agentic AI Changes What Application Security Has to Cover
A human employee who wants to delete a customer record, issue a refund, or push a config change has to ask, click, and confirm. An AI agent doing the same thing can plan, decide, and execute the action in one pass, often through a tool it picked itself, in a sequence no one explicitly approved.
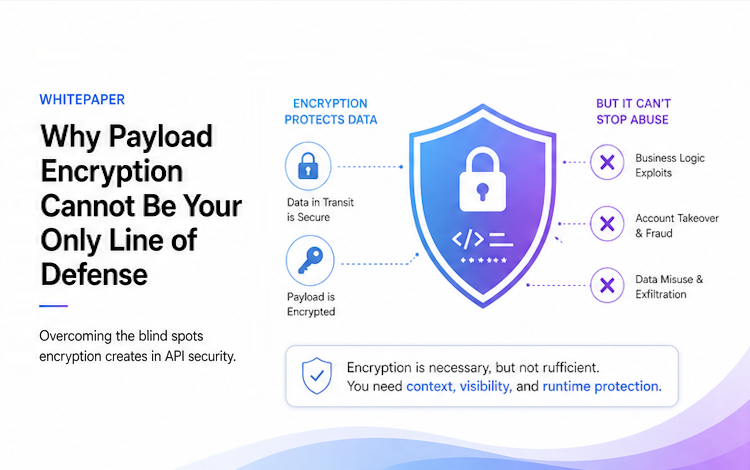
That shift, from systems that respond to systems that act, is why most application security stacks fall short the moment agentic AI enters the picture. Web Application Firewalls (WAFs) and API gateways were built to evaluate whether a request is well-formed. They were never built to evaluate whether an autonomous decision made sense.
Enterprises rolling out agentic AI in 2026 are converging on the same five use cases to close that gap. Each one answers a different question about how agents behave, and together they form something closer to a lifecycle than a checklist.
AI Discovery
Most enterprises don’t have a clean inventory of their AI footprint. Developers spin up agents inside CI/CD pipelines. Business teams plug LLM features into SaaS tools. Someone stands up an MCP server over a weekend to solve one problem and never tells security. None of this shows up in an asset register built for servers and endpoints.
AI discovery is the continuous process of finding every agent, model, MCP server, tool, and execution path running in your environment, not just the ones that went through formal review.
- Maps shadow agents and undocumented MCP servers, not just sanctioned deployments
- Tracks execution paths continuously, since the agentic AI environment changes faster than quarterly audits can capture
- Feeds every other control on this list; you cannot assess posture, red-team, or enforce runtime guardrails on an agent you don’t know exists
AppSentinels’ Continuous Discovery capability automatically maps every AI agent, MCP server, tool, and execution path across your environment, eliminating the blind spots that shadow AI creates before they turn into incidents.
AI Security Posture Management (AI-SPM)
Once you know what’s running, the next question is whether it’s configured safely. An agent with a broad OAuth scope, a model connected to a sensitive data source with no guardrails, a tool allowlist that was correct three weeks ago but never updated, these are posture problems, and they’re invisible at runtime until someone exploits them.
AI Security Posture Management (AI-SPM) continuously assesses risk across AI decisions, data access, and business impact, surfacing the misconfigurations and permission gaps before an attacker finds them in production.
- Flags excessive agent permissions and overly broad tool access before deployment
- Detects policy drift as agents, models, and MCP integrations change over time
- Links configuration risk to business impact, not just a generic severity score
Posture management reduces the size of the attack surface. It doesn’t, on its own, tell you whether that remaining surface can actually be exploited, which is where red-teaming comes in.
AI Red-Teaming
QA confirms an agent does what it’s supposed to do under expected conditions. It says nothing about what the agent does when someone deliberately tries to manipulate it. Prompt injection, tool poisoning, and intent drift are adversarial failure modes, and they rarely show up in a functional test suite because they depend on inputs a normal user would never send.
AI red-teaming proactively simulates workflow manipulation, prompt injection, and business logic abuse against live agentic workflows, before attackers run the same simulation for real.
- Tests whether hidden instructions in a document, email, or tool description can redirect agent behavior
- Simulates privilege escalation chains across multi-agent and multi-tool workflows
- Runs continuously as workflows change, not as a one-time pre-launch exercise
AppSentinels’ AI Red-Teaming capability functions like a dedicated pen-testing team running against your AI workflows continuously, surfacing the exploit classes that standard QA and CVE scanning were never designed to catch.
Red-teaming finds the gap before launch. Runtime protection is what catches the attack that gets through anyway.
AI Runtime Protection
A WAF can tell you a request is syntactically valid. It cannot tell you whether an LLM’s decision to issue a refund, delete a record, or call an external API was a legitimate action or the result of a hidden instruction buried in a tool description. The threat isn’t in the packet. It’s in the agent’s intent.
AI runtime protection enforces real-time guardrails on AI-driven actions, evaluating agent behavior and tool calls as they happen, without forcing a trade-off between security and agent autonomy or speed.
- Evaluates agent intent at the moment of action, not just whether the request matches an approved schema
- Detects when prompt injection redirects an agent toward an unauthorized action, even when the specific tool is on an approved list
- Blocks business logic abuse and OWASP API/LLM Top 10 risks inline, without adding latency that breaks the agent experience
This is the layer that has to hold when discovery, posture management, and red-teaming have all done their job and an attacker still finds a way in. AppSentinels’ Runtime Protection inspects agent actions semantically in real time, closing the gap between a request that looks valid and an action that actually is.
MCP Security
It’s tempting to treat MCP as just another API surface. The assumption breaks down fast. Traditional APIs are deterministic: known endpoints, explicit parameters, a fixed set of actions. MCP-powered agents operate through inferred intent and dynamic tool chaining, an agent might use Tool A and Tool B today and Tools C, D, and E tomorrow to solve the same task, depending on how the input was phrased.
MCP Security protects the protocol layer connecting agents to the tools, data, and systems they act on, with controls designed around execution behavior rather than fixed schemas.
- Discovers every MCP client, server, and tool connection, including shadow deployments that skipped review
- Filters tool-listing responses at the gateway so agents only ever see tools they’re permitted to call
- Applies semantic anomaly detection to catch intent drift and context poisoning that signature-based controls miss
AppSentinels’ MCP Security capability secures agent-to-tool interactions and AI runtime flows with the semantic guardrails that existing API controls structurally cannot provide.
Why Do These Five Use Cases Need to Work Together, Not as Point Solutions?
Each use case answers a question the others can’t. Discovery tells you what exists. Posture management tells you whether it’s configured safely. Red-teaming tells you whether it can be broken. Runtime protection tells you whether an attack is happening right now. MCP security threads through all four, since MCP is increasingly the layer agents use to actually act.
Deployed as separate point tools, these create the same blind spots they’re meant to close: a discovery tool that doesn’t talk to your runtime monitor, a red-team finding that never makes it into a posture baseline. The throughline that connects them is business logic, the actual sequence of valid-looking actions an agent takes across a workflow, not just whether any single request or tool call was technically authorized.
AppSentinels unifies Agentic AI, MCP, and API security in a single control plane built around exactly that throughline: a live Business Logic Graph that maps how agents, tools, and APIs interact, so discovery findings inform posture baselines, red-team results harden runtime guardrails, and every layer enforces against the same intent-aware context.
Most agentic AI security programs in 2026 are still early, with significant gaps between how fast agents are deployed and how well they’re governed. The enterprises closing that gap aren’t buying five disconnected tools. They’re building toward a single lifecycle where what gets discovered today shapes what gets protected tomorrow.
Request a Demo to get a walkthrough of how AppSentinels maps discovery, security posture, red-teaming, runtime protection, and MCP security into one control plane.
Frequently Asked Questions
1. What is agentic AI security?
2. How is MCP security different from API security?
3. Why does AI need red-teaming if it already goes through QA?
4. What is the difference between AI-SPM and AI runtime protection?
5. How should enterprises start securing agentic AI workflows?